¿Qué
son los sistemas de archivos?
Un sistema de
archivos son los métodos y estructuras de datos que un sistema operativo
utiliza para seguir la pista de los archivos de un disco o partición; es decir,
es la manera en la que se organizan los archivos en el disco. El término
también es utilizado para referirse a una partición o disco que se está
utilizando para almacenamiento, o el tipo del sistema de archivos que utiliza.
Así uno puede decir “tengo dos sistemas de archivo” refiriéndose a que tiene
dos particiones en las que almacenar archivos, o que uno utiliza el sistema de
“archivos extendido”, refiriéndose al tipo del sistema de archivos.
La diferencia
entre un disco o partición y el sistema de archivos que contiene es importante.
Unos pocos programas (incluyendo, razonablemente, aquellos que crean sistemas
de archivos) trabajan directamente en los sectores crudos del disco o
partición; si hay un archivo de sistema existente allí será destruido o
corrompido severamente. La mayoría de programas trabajan sobre un sistema de
archivos, y por lo tanto no utilizarán una partición que no contenga uno (o que
contenga uno del tipo equivocado).
Antes de que una
partición o disco sea utilizada como un sistema de archivos, necesita ser
iniciada, y las estructura de datos necesitan escribirse al disco. Este proceso
se denomina construir un sistema de archivos.
La mayoría de los
sistema de archivos UNIX tienen una estructura general parecida, aunque los
detalles exactos pueden variar un poco. Los conceptos centrales son superbloque,
nodo-i, bloque de datos, bloque de directorio, y bloque
de indirección. El superbloque tiene información del sistema de archivos en
conjunto, como su tamaño (la información precisa aquí depende del sistema de
archivos). Un nodo-i tiene toda la información de un archivo, salvo su nombre.
El nombre se almacena en el directorio, junto con el número de nodo-i. Una
entrada de directorio consiste en un nombre de archivo y el número de nodo-i
que representa al archivo. El nodo-i contiene los números de varios bloques de
datos, que se utilizan para almacenar los datos en el archivo. Sólo hay espacio
para unos pocos números de bloques de datos en el nodo-i; en cualquier caso, si
se necesitan más, más espacio para punteros a los bloques de datos son
colocados de forma dinámica. Estos bloques colocados dinámicamente son bloques
indirectos; el nombre indica que para encontrar el bloque de datos, primero hay
que encontrar su número en un bloque indirecto.
Sistemas
de archivos soportados por Linux
Linux soporta una
gran cantidad de tipos diferentes de sistemas de archivos. Para nuestros
propósitos los más importantes son:
minix
El
más antiguo y supuestamente el más fiable, pero muy limitado en características
(algunas marcas de tiempo se pierden, 30 caracteres de longitud máxima para los
nombres de los archivos) y restringido en capacidad (como mucho 64 MB de tamaño
por sistema de archivos).
xia
Una
versión modificada del sistema de archivos minix que eleva los límites de
nombres de archivos y tamaño del sistema de archivos, pero por otro lado no
introduce características nuevas. No es muy popular, pero se ha verificado que
funciona muy bien.
ext3
El
sistema de archivos ext3 posee todas las propiedades del sistema de archivos
ext2. La diferencia es que se ha añadido una bitácora (journaling). Esto mejora
el rendimiento y el tiempo de recuperación en el caso de una caída del sistema.
Se ha vuelto más popular que el ext2.
ext2
El
más sistema de archivos nativo Linux que posee la mayor cantidad de
características. Está diseñado para ser compatible con diseños futuros, así que
las nuevas versiones del código del sistema de archivos no necesitará rehacer
los sistemas de archivos existentes.
ext
Una
versión antigua de ext2 que no es compatible en el futuro. Casi nunca se
utiliza en instalaciones nuevas, y la mayoría de la gente que lo utilizaba han
migrado sus sistemas de archivos al tipo ext2.
reiserfs
Un
sistema de archivos más robusto. Se utiliza una bitácora que provoca que la
pérdida de datos sea menos frecuente. La bitácora es un mecanismo que lleva un
registro por cada transacción que se va a realizar, o que ha sido realizada.
Esto permite al sistema de archivos reconstruirse por sí sólo fácilmente tras
un daño ocasionado, por ejemplo, por cierres del sistema inadecuados.
¿Qué
sistemas de archivos deben utilizarse?
Existe
generalmente poca ventaja en utilizar muchos sistemas de archivos distintos.
Actualmente, el más popular sistema de archivos es ext3, debido a que es un
sistema de archivos con bitácora. Hoy en día es la opción más inteligente.
Reiserfs es otra elección popular porque también posee bitácora. Dependiendo de
la sobrecarga del listado de estructuras, velocidad, fiabilidad (percibible),
compatibilidad, y otras varias razones, puede ser aconsejable utilizar otro
sistema de archivos. Estas necesidades deben decidirse en base a cada caso.
Un sistema de
archivos que utiliza bitácora se denomina sistema de archivos con bitácora. Un
sistema de archivos con bitácora mantiene un diario, la bitácora, de lo que ha
ocurrido en el sistema de archivos. Cuando sobreviene una caída del sistema, o
su hijo de dos años pulsa el botón de apagado como el mío adora hacer, un
sistema de archivos con bitácora se diseña para utilizar los diarios del
sistema de archivos para recuperar datos perdidos o no guardados. Esto reduce la
pérdida de datos y se convertirá en una característica estándar en los sistemas
de archivos de Linux. De cualquier modo, no extraiga una falsa sensación de
seguridad de esto. Como todo en esta vida, puede haber errores. Procure siempre
guardar sus datos para prevenir emergencias.
Crear
un sistema de archivos
Un sistema de
archivos se crea, esto es, se inicia, con el comando mkfs. Existen en
realidad programas separados para cada tipo de sistemas de archivos. mkfs
es únicamente una careta que ejecuta el programa apropiado dependiendo del tipo
de sistemas de archivos deseado. El tipo se selecciona con la opción -t fstype.
Los programas a
los que -t fstype llama tienen líneas de comando ligeramente diferentes. Las
opciones más comunes e importantes se resumen más abajo; vea las páginas de
manual para más información.
-t fstype
Selecciona
el tipo de sistema de archivos.
-c
Busca
bloques defectuosos e inicia la lista de bloques defectuosos en consonancia.
-l filename
Lee
la lista inicial de bloques defectuosos del archivo dado.
Para crear un
sistema de archivos ext2 en un disquete, se pueden introducir los siguiente
comandos:
$ fdformat -n /dev/fd0H1440
Double-sided, 80 tracks, 18 sec/track. Total
capacity
1440 kB.
Formatting ... done
$ badblocks /dev/fd0H1440 1440 $>$
bad-blocks
$ mkfs -t ext2 -l bad-blocks
/dev/fd0H1440
mke2fs 0.5a, 5-Apr-94 for EXT2 FS 0.5, 94/03/10
360 inodes, 1440 blocks
72 blocks (5.00%) reserved for the super user
First data block=1
Block size=1024 (log=0)
Fragment size=1024 (log=0)
1 block group
8192 blocks per group, 8192 fragments per group
360 inodes per group
Writing inode tables: done
Writing superblocks and filesystem accounting information:
done
$
Primero el
disquete es formateado (la opción -n impide la validación, esto es, la
comprobación de bloques defectuosos). A continuación se buscan los bloques
defectuosos mediante badblocks, con la salida redirigida a un archivo, bad-blocks.
Finalmente, se crea el sistema de archivos con la lista de bloques defectuosos
iniciada con lo que hubiera encontrado badblocks.
Tipos de particiones
Hay dos clases de
particiones: primarias y extendidas.
Una partición primaria es una
única unidad lógica para el ordenador. Además puede ser reconocida como una
partición de arranque.
En cambio la partición
extendida puede tener más de una unidad lógica. Tampoco es una unidad de
arranque.
La partición primaria puede contener un sistema operativo para arrancar.
Una de las particiones primarias se llama la partición activa y es la de
arranque. El ordenador busca en esa partición activa el arranque del sistema.
Cuando hay varios sistemas
operativos instalados, la partición activa tiene un pequeño programa llamado gestor
de arranque, que presenta un pequeño menú que permite elegir qué sistema
operativo se arranca.
En un disco puede haber 4 particiones primarias o 3 primarias y 1 extendida.
Cuando se crean las
particiones, se graba en el sector de arranque del disco (MBR), una pequeña
tabla que indica dónde empieza y dónde acaba cada partición, el tipo de
partición que es y si es o no la partición activa.
Resumiendo, podemos
considerar tres tipos de particiones:
La primaria: La puede
utilizar como arranque el MBR (sector de arranque) del disco.
La extendida: no la puede utilizar el MBR como arranque. Se inventó para romper
la limitación de 4 particiones primarias en un disco. Es como si se tratara de
una primaria subdividida en lógicas más pequeñas.
La partición lógica: ocupa parte de la extendida o su totalidad.
Algunos sistemas operativos modernos se pueden instalar en cualquier tipo de
partición, pero el sector de arranque del disco necesita una primaria. Por lo
demás no hay diferencia entre ellas en cuanto a rendimiento.
Si está instalando el sistema operativo por primera vez, puede aprovechar la
instalación para establecer un mínimo de tres particiones (una primaria y una
extendida con dos unidades lógicas), así deja dos primarias disponibles para el
futuro. Deje espacio del disco sin asignar para definir con posterioridad,
particiones nuevas.






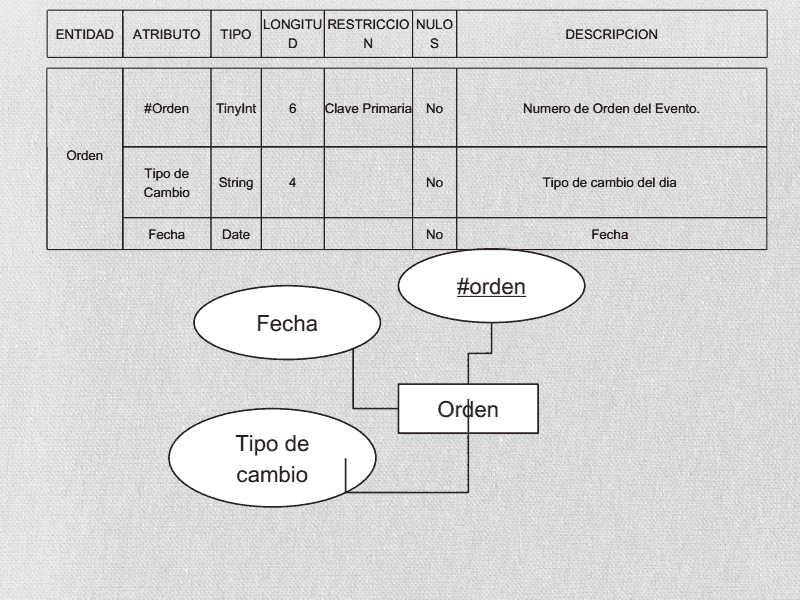










.bmp)
.bmp)
.bmp)
.bmp)
.bmp)




.bmp)
.bmp)
.bmp)